Welcome
Scroll Down
I'll add it later~
I'll add something later, too~
During this week's workshop, I learned how to use web-scraping tools for data collection and gained a deeper understanding of webpage elements. By analyzing the source code of web pages, I gradually mastered how to locate and extract the required data, which gave me a deeper understanding of how to collect and process internet data.
Especially during the practical use of web-scraping tools, I discovered the complex technical logic behind data collection. In the past, collecting data for me might have been simply visiting a webpage and copying the content, but now, through writing code and using web-scraping software, I can automate this process efficiently. This skill is highly useful for large-scale data analysis, and it made me realize the importance of technology in modern research.
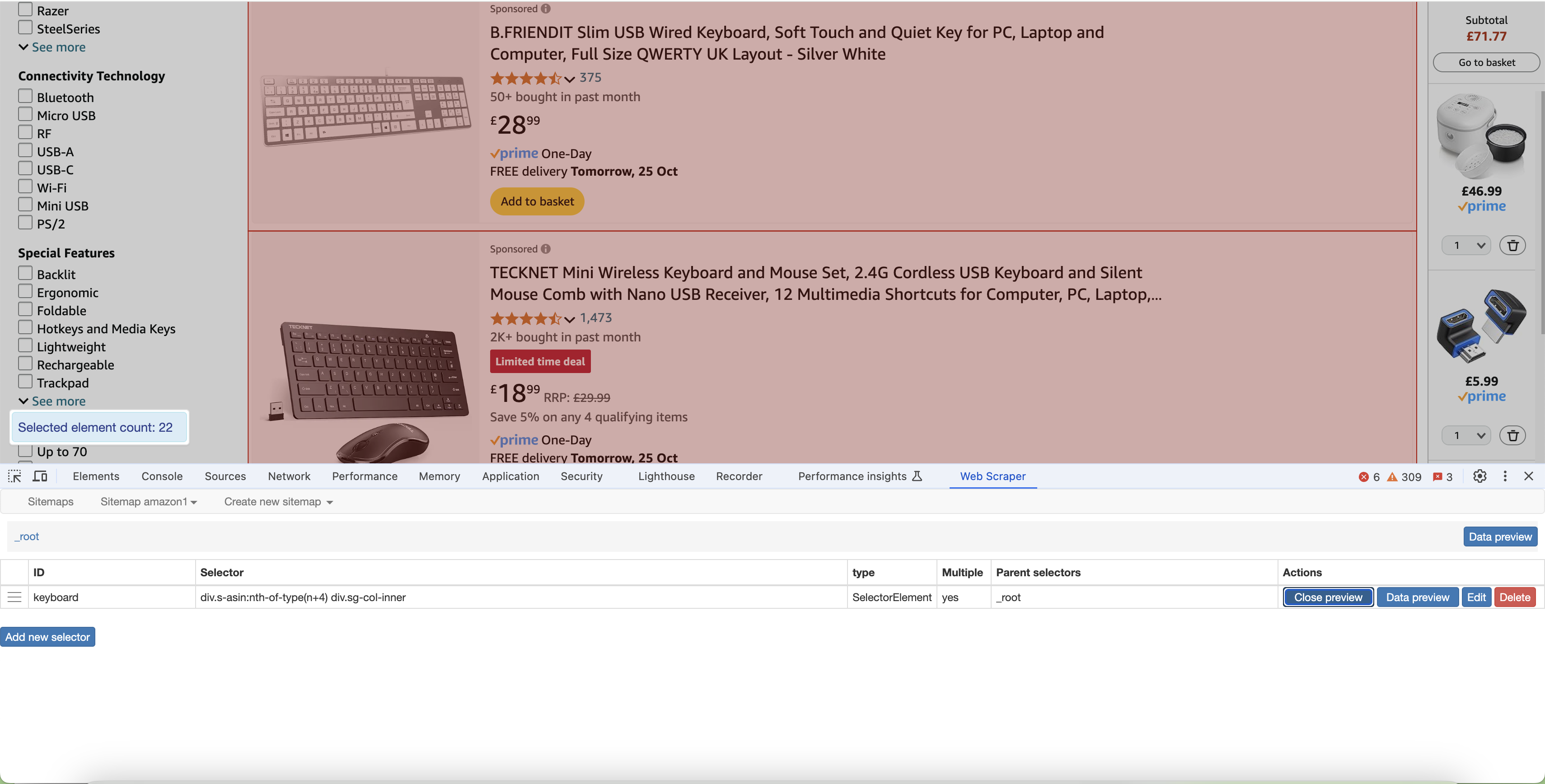
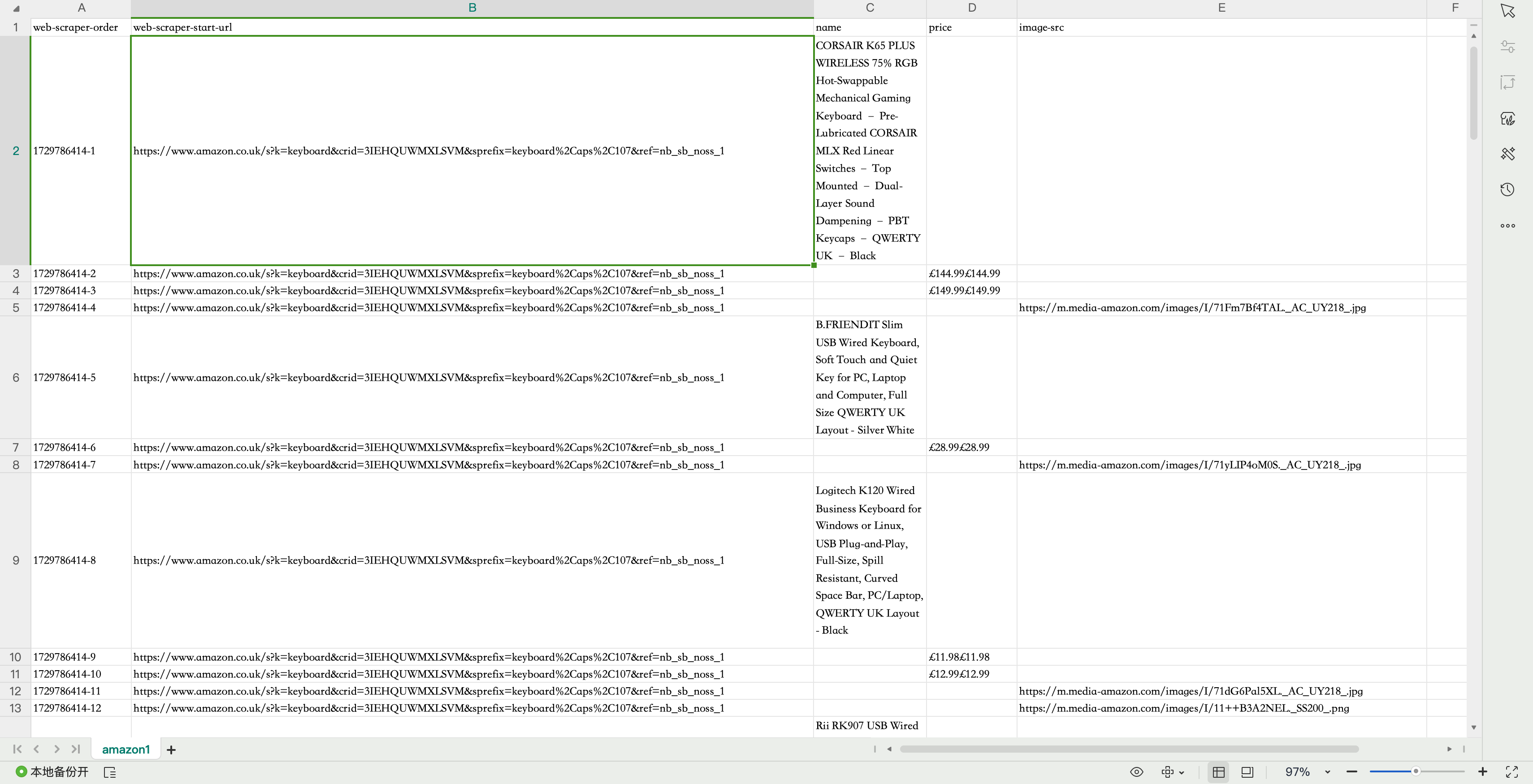
After learning how to use web scraping tools, I applied this skill to a practical project, attempting to scrape product information from the Amazon website. To achieve this, I selected "keyboards" as the target for data collection and set up three selectors: product name, price, and image.
In my initial attempts, I encountered some difficulties, mainly due to the complexity of the webpage structure and the dynamic loading of content. However, through continuous adjustment of the selectors and analysis of the HTML structure of the webpage, I gradually learned how to precisely locate the desired data. Ultimately, I successfully extracted multiple sets of product names, prices, and corresponding image links.
In this week's work, we had the opportunity to explore machine learning through Teachable Machine, focusing on training models with images, voices, and poses. This was an engaging experience that provided hands-on insights into how machine learning models function and respond to real-world inputs. One of the most exciting aspects was the simplicity of Teachable Machine, which allowed us to experiment and see the results quickly. However, as we worked with these models, we noticed some limitations. For instance, factors like background color, lighting, and other environmental conditions can significantly affect the model’s accuracy. This revealed how sensitive machine learning models can be to small changes in the data they are trained on. These challenges made me appreciate the complexities involved in developing robust models that can handle diverse real-world scenarios. The process highlighted the importance of high-quality data for training effective models and underscored the need for proper calibration and testing. This experience also reminded me of another software I had previously used, RVC, which is based on voice models for voice modulation. The RVC software demonstrated how machine learning can be applied to audio data to create real-time transformations, such as altering pitch, tone, and even emulating different voices. The similarities between Teachable Machine and RVC were striking, especially in terms of how both models require quality input and careful tuning to achieve optimal results.